데이터베이스 중간고사
1. 데이터베이스 환경
데이터-> 사실
정보-> 의미
P(D)=I: 처리기를 통해 데이터를 가공하면 정보가 된다.
절차 지향 언어: C언어와 같이 순서대로 차곡차곡 프로그래밍 하여 쌓는 것
객체 지향 언어: 리모콘과 모니터의 관계처럼 각자의 객체가 서로 메세지를 송신 수신하여 주고받는 관계
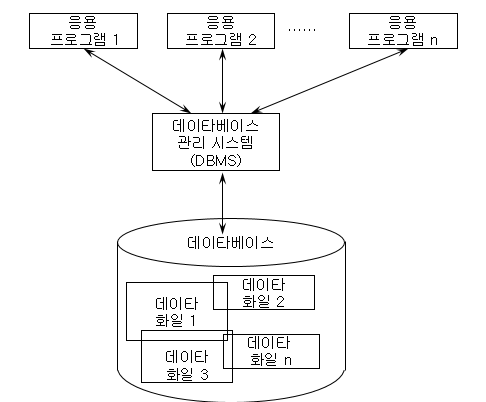
DBMS의 필수 기능 3가지
1. 정의기능: 데이터의 논리적,물리적 구조를 명세하여 하나의 저장 구조로 여러 사용자의 요구를 지원할 수 있도록 데이타를 조직하는 기능
2. 조작기능: 데이터를 조작하는 소프트웨어가 요청하는 데이터의 검색, 삽입, 수정, 삭제 작업을 지원
3. 제어기능: 데이터 베이스사용자를 생성하고 모니터링하며 접근을 제어한다. 데이터의 정확성과 보안성을 유지한다.
모델링: 프로그램 개발 이전에 의뢰인에게 보여주는것 (프로그램 개발 완성가지 유지 보수 기간이 길기 때문이다.)
개발자는 시스템을 프로그래밍 하기 전에 많은 요소를 고민하고 결정을 내린다.
1. 어떤 기능을 제공할 것인가
2. 사용자 인터페이스는 어떻게 제작할 것인가
3. 어떤 클래스들이 필요한가 등은 개발자가 소스 코드를 작성하기 전에 미리 결정해야 하는 사항이다.
비쥬얼 스튜디오 같은 개발 도구는 개발 툴이라고 부르고, starUML 같은 프로그래밍 모델링 툴은 CASE 툴이라고 부른다.
그렇다면 데이터 모델링은 어떻게 하는 것일까? 소프트웨어 설계가 건축 설계라면 데이터베이스는 지반 설계와 같다.
현실 세계 개념-> 개념적 모델( ER 다이어그램)->논리적 모델(관계 데이터 모델)->데이터베이스(물리적 구조)
우선 데이터 모델링에선 ER 모델을 이용한다.
데이터 모델: D=<S,O,C>: 데이터의 구조 structure(정적 성질), 연산 operation(동적 성질), 제약 조건 constraint(한계 표현)

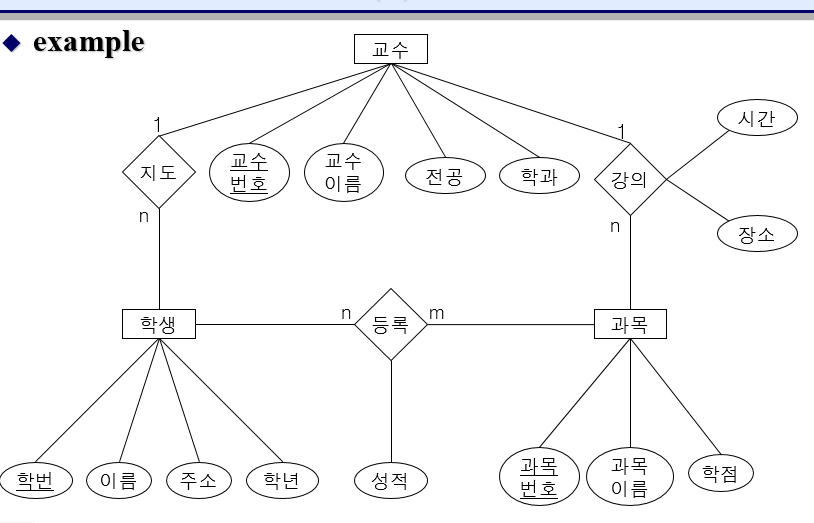
관계 데이터 모델
데이터 모델은 네트워크 데이터 모델, 계층 데이터 모델, 관계 데이터 모델, 객체-관계 데이터 모델 등이 있다. 이 중에서 관계 데이터 모델이 가장많이 사용된다.
관계 데이터 모델은 사용자들이 데이터에 접근하기 쉬운 테이블 형태로 데이터 간의 관계를 표현한다. 집합 형태의 테이블 단위로 처리한다.
관계 데이터 모델은 1970년대 IBM 연구소의 에드가 코드 박사가 수학의 집합 이론에 근거하여 제한하여 이론적인 토대가 탄탄하다.
각 집합의 원소들이 관계를 맺는 방법은 집합연산자인 카티션 프로덕트(연산자 기호 X)를 사용한다.
릴레이션 간의 관계는 식별 가능한 '값'을 이용하여 표현한다.
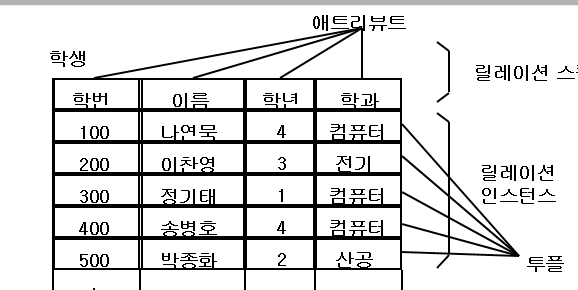
스키마는 관계 데이터베이스의 릴레이션이 어떻게 구성되는지, 어떤 정보를 담고 있는지에 대한 기본적인 구조를 정의한다. 테이블에서 스키마는 헤더에 나타나며 각 제이터의 특징을 나타내는 속성, 자료 타입 등의 정보를 담고 있다.
인스턴스는 정의된 스키마에 따라 테이블에 실제로 저장되는 데이터의 집합을 의미한다.
데이터베이스
테이블(릴레이션의 집합): 행과 열로 구성
개체 릴레이션,관계 릴레이션
Relation Scheme: 개체와 관계성을 테이블로 정의

릴레이션의 특성
1. 투플의 유일성: 릴레이션 내 중복된 투플을 허용하지 않는다.
2. 투플들의 무순서: 투플의 순서가 상관 없다.(데이터 삭제, 수정, 삽입에 따라 순서가 바뀔 수 있다)
3.애트리뷰트들의 무순서: 속성의 순서가 상관 없다.
4.애트리뷰트의 원자값(분해 불가능): 속성은 단일 값을 가진다.한 속성의 값은 모두 같은 도메인 값을 가진다.
관계 데이터 제약-무결성 제약조건
키(Key): 투플을 유일하게 식별할 수 있는 애트리뷰트 집합
키는 각 릴레이션의 투플을 유일하게 식별하는 장치이며 동시에 각 릴레이션 간의 관계를 말해 주는 연결고리이다.
Key attribute
개체 집합 내에 각 개체마다 다른 값을 갖는 애트리뷰트
동일한 키 값을 갖는 두 개의 객체 인스턴스는 없음
E-R 다이어그램 상에서 밑줄로 표시 ex. 번호
후보키(Candidate Key)
후보키는 유일하게 식별할 수 있는 최소한의 속성 집합이다.
이름은 슈퍼키는 될 수 있지만 후보키는 될 수 없다. 번호키가 대표적인 후보키이다.
즉 최소성과 유일성을 가지면 후보키이다
기본키(Primary Key)
기본키는 여러가지 후보키 중 하나를 선정하여 대표로 삼는 키이다.
기본키는 릴레이션 내에서 투플을 식별할 수 있는 고유한 값을 가져야 한다.
NULL 값은 허용하지 않는다. 키값의 변동이 일어나지 않아야 한다.
대리키/대체키(alternate key)
기본키 이외의 후보키
외래키(foreign key)
다른 릴레이션의 기본키를 참조하여 관계 데이터 모델의 특징인 릴레이션 간의 관계를 표현한다.
기본키와 달리 NULL 값을 표현할 수 있고, 중복값도 허용한다.
무결성 제약
데이터 무결성은 데이터 베이스에 저장된 데이터의 일관성과 정확성을 지키는 것을 말한다.
실제 데이터의 삽입, 삭제, 수정에 관련된 문제는 응용 프로그래밍 개발 단계에서도 프로그래머가 일일이 처리할 수 있다. 그러나 모든 경우를 감안하여 프로그래머가 직접 프로그래밍하면 프로그램을 작성하기도 어렵고 유지하기도 어렵다.
무결성 제약조건은
투플에 삽입 가능한 데이터의 값을 제한하는 도메인 무결성 제약조건과
데이터 모델의 핵심인 관계 표현을 위한 개체 무결성 제약조건, 참조 무결성 제약조건이 있다.
도메인 무결성 제약조건은 투플들이 각 속성의 도메인에 저장된 값만을 가져야 한다.
개체 무결성 제약조건은 기본키(primary key)제약 조건이라고도 부른다. 기본키는 NULL 값을 가져서는 안되며 릴레이션 내 오직 하나의 값만을 가져야 한다는 조건이다.
참조 무결성 제약조건은 외래키(foreign key)제약 조건이라고도 부른다. 릴레이션 간의 참조 관계를 선언하는 제약 조건이다. 외래키의 값은 참조된 릴레이션의 기본키 값이거나 null이다.
관계대수와 관계해석
관계대수는 데이터를 추출하는 데 사용하는 언어이다.
코드 박사는 관계대수와 관계해석을 관계 데이터 모델을 사용하는 데 필요한 언어로 소개하였다.
관계 대수는 어떤 데이터를 어떻게 찾는지에 대한 처리 절차를 명시하는 절차적인 언어이다.
관계 해석은 어떤 데이터를 찾는지만 명시하는 선언적인 언어이다.
집합에서 가능한 연산은 합집합, 교집합, 카티션 프로덕트(X) 등이 있다.
릴레이션의 개수는 모든 부분집합의 수이다.
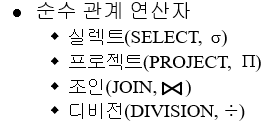
순수 관계연산:
셀렉션 selection(sigma) -> 릴레이션에서 조건을 만족하는 투플을 선택한다.
프로젝션 projection -> 릴레이션의 속성을 선택한다.
조인 join -> 유도, 이항
디비젼 division -> 부모 릴레이션에 포함된 투플의 값을 모두 가진 투플을 분자 리레이션에서 추출
개명 rename -> 릴레이션의 속성이나 이름을 변경한다.
일반 집합연산: 합집합, 교집합, 차집합, 카티션 프로덕트(X)
